

Ready to turn creative testing into a repeatable system? Try Stage in Bïrch.
Most Meta ad creatives don’t get a long runway. In many accounts, fatigue can appear within a couple of weeks. At scale, it can happen even faster.
If your team is testing creative in the same way you did two or three years ago, more volume won’t necessarily improve results. Even with great creative, a testing process that hasn’t kept pace with how the platform has changed could mean you lose ground.
This is the reality of Meta advertising in 2026. Creative volume has exploded, privacy-driven signal loss has made performance data murkier, and Meta’s own automation and broad targeting have fundamentally changed what it means to test.
Instead of running isolated tests and waiting to see what sticks, you’re feeding a system that decides who sees your ads, when, and how often. If your testing system isn’t built around that reality, you may misread what’s actually driving results.
In this guide, we’ll go through what creative testing looks like in 2026, how to build a Meta-specific creative testing framework that actually works, and some common mistakes to avoid.
Why creative testing on Meta looks different in 2026
Meta advertising in 2026 is fundamentally different from even two years ago.
Advantage+ sales campaigns and dynamic creative optimization mean Meta is actively deciding which creative gets shown, to whom, and when. This means your test structure needs to work with the algorithm, not around it. Clean ad sets, minimal simultaneous variables, and enough spend to generate a meaningful signal before drawing conclusions are now the baseline.
The learning phase also affects how tests behave. Every time you create a new ad set, edit one that’s already running, or change the campaign structure, Meta resets the learning phase.
An ad set needs roughly 50 optimization events in a seven-day window to exit learning. Try to build longer test windows than you think you need, resist the urge to optimize mid-flight, and consider whether an ad set has exited learning before interpreting results.
Signal loss adds another layer of complexity.
Since iOS 14.5, Aggregated Event Measurement, delayed reporting, and modelled conversions have reshaped what performance data actually looks like. Early winners based on incomplete attribution can be misleading. A creative that looks like a winner on day three may not be performing so well on day 10.
That’s why statistical confidence, holdout testing, and cross-campaign comparison are now essential for making solid decisions.
Creative fatigue is also accelerating. With more advertisers competing for attention and users scrolling through more content than ever, audiences see ads more frequently than before.
At the same time, Meta’s algorithm tends to push the best-performing creatives more aggressively. Individual ads are burning out faster, and refresh cycles that once ran quarterly often need to happen monthly (or even sooner for high-spend accounts).
What creative testing on Meta actually means today
The three things that define modern creative testing are:
- Hypothesis-first thinking: Every test should answer a specific question. “Does leading with a customer testimonial outperform a product demo for a cold audience?” is more comprehensive than “Which creative performs better?”
- Iteration velocity: Teams that consistently test more creative variations often discover winning ads faster than teams testing only a few.
- Decision rules: Define in advance what “winning” means (CPA threshold, CTR lift, ROAS delta) so you’re not making emotional calls when the data comes in.
Core creative testing methodologies on Meta (and when to use each)
A/B testing inside Meta experiments
Meta’s native A/B testing tool (via Experiments) splits your audience randomly and assigns each segment to a single creative variant. It’s the gold standard for statistical integrity because it eliminates auction overlap.
🏆 Best for: Concept-level tests where you need clean, defensible results, particularly when comparing fundamentally different creative angles such as UGC vs studio content, static vs video formats, or direct-response messaging vs brand-led creative.
🚩 Watch out for: Cost and minimum spend requirements. Native A/B tests are expensive for small accounts. They also need 1–2 weeks minimum to reach significance, which means you’re burning budget on a test with delayed learning.
Ad ranking (auction-based testing)
This is the approach most teams default to without realizing—running multiple creatives in the same ad set and letting Meta’s algorithm prioritize delivery to the best performer.
🏆 Best for: Execution-level testing at volume, when you have already validated a concept and want to find the best hook, visual, or CTA variation quickly.
🚩 Watch out for: The algorithm has a recency bias. Newer creatives often underperform initially because they lack historical signals, so early results can be misleading. It’s also important to ensure there is sufficient statistical confidence before declaring a winner.
Use Bïrch Rules to automatically pause underperforming ads after a defined spend threshold and protect your learning phase from early data pulling budget to the wrong creative. Once your rules are running, Bïrch AI analyses your full rule setup and ad account data to surface the contradictions, the blind spots, and the setups worth doubling down on. You review the suggestions and decide what to implement.
Iterative (sequential) testing for creative volume
Rather than running everything simultaneously, iterative testing works in rounds.
- Round 1 validates the concept (e.g., UGC vs brand video).
- Round 2 tests execution within the winner (3 different hooks on the UGC format).
- Round 3 optimizes details (CTA copy, thumbnail frame, aspect ratio).
🏆 Best for: Teams that are scaling with consistent creative output. This approach compounds learnings over time and builds a reusable insight bank.
🚩 Watch out for: Sequential testing takes time. If your creative production pipeline is slow, you risk learning from stale data.
Concept testing vs. execution testing
Many teams conflate the two.
- Concept testing evaluates the strategic idea. You’re asking: “Does this creative angle resonate with our audience at all?”
- Execution testing evaluates production variables within a concept that’s already been proven to work. Which hook line performs better?
Execution testing should come after the concept has shown some initial traction. Otherwise, teams can spend time optimizing small elements, such as a CTA or hook, before confirming that the underlying creative angle actually resonates with the audience.
How to build a scalable Meta creative testing workflow
This five-step framework can help you build a system that drives results and lets you scale fast.
Phase 1: Create a clear, testable hypothesis.
Before any brief is written or creative produced, answer: What do we believe the results will be? Why? What would change our minds?
Good hypotheses are specific. For example: “We believe a customer-facing UGC video showing a 30-day result will outperform our current studio asset for women aged 28–44 because our CRM data shows this segment responds to social proof over product aesthetics.”
Hypothesis inputs should come from: qualitative research, competitor creative analysis, customer interview themes, and performance patterns in your existing creative data.
Phase 2: Launch the test under controlled conditions.
Set your test parameters before launch:
- One variable per test
- Matched budgets, bid strategies, and targeting across all variants
- A defined runtime (minimum 7 days and 14 for lower-volume accounts)
- A pre-defined success metric (primary KPI + significance threshold)
Phase 3: Interpret the data.
The first 72 hours can be misleading. Resist the urge to read data for a minimum of seven days.
For conversion-optimized campaigns, 10–14 days is more reliable given learning phase timelines and attribution windows.
Phase 4: Systematically scale validated winners.
When you have a validated winner, add it to your core campaign structure straight away. Don’t wait for a formal review cycle. Creative lifespan on Meta is limited, and waiting reduces the window where it can drive peak performance.
Scale by adding the winning creative to fatigued ad sets rather than pausing and rebuilding (which resets learning). Duplicate to replicate across campaigns cleanly.
Phase 5: Retire what no longer performs
Rather than waiting for a creative to fully fail, it can help to define performance floor triggers that signal when an ad may be nearing fatigue.
For example, a creative might be flagged for review if CTR drops more than 30% from its peak or if frequency passes a defined threshold.
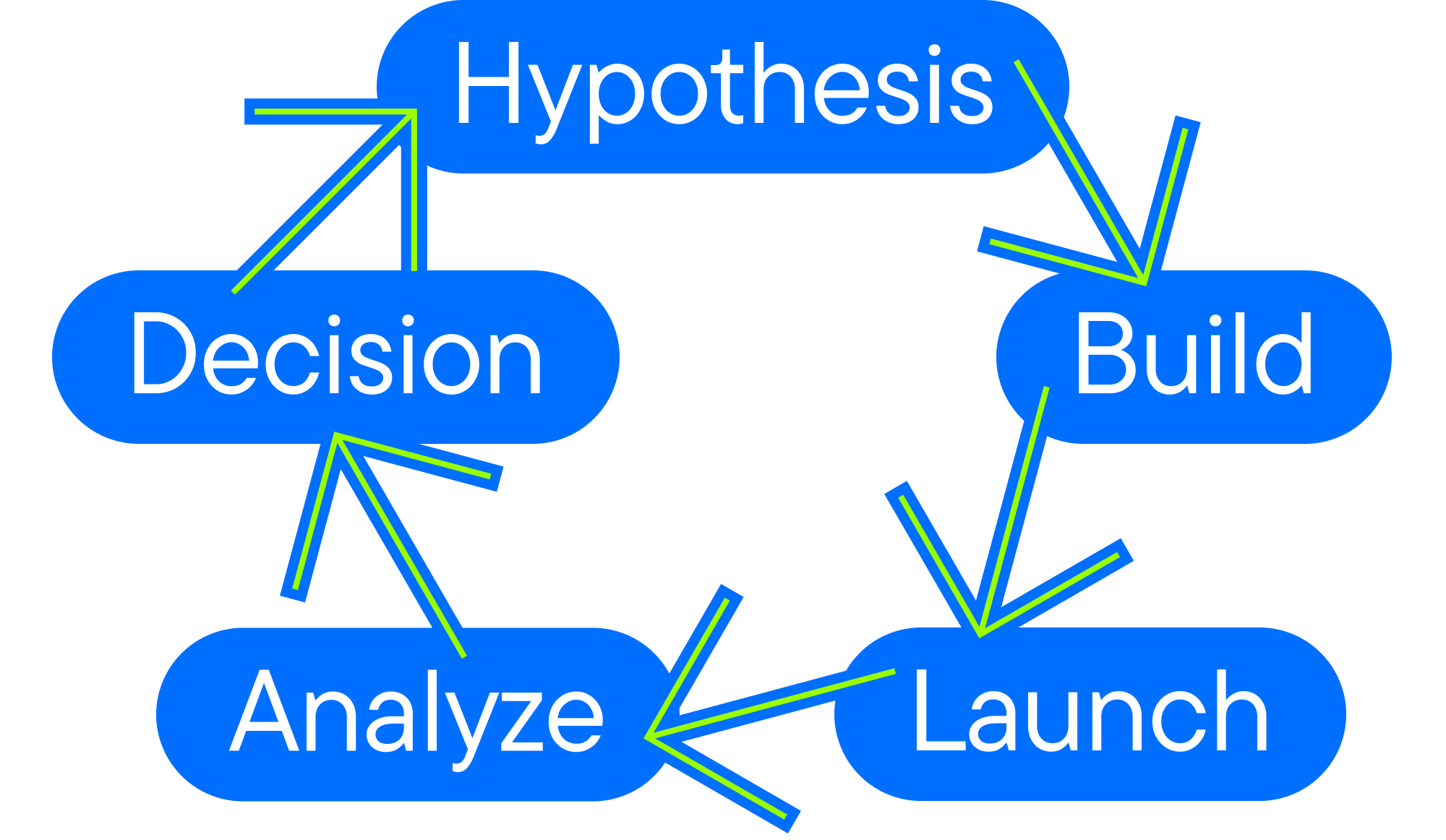
Campaign setup and test phases that actually work
Exploration phase: Early-funnel creative testing should operate in a dedicated exploration campaign, separate from your performance campaigns. The goal is to find out which concepts have the potential to perform.
- Structure: Ad Set Budget Optimization, separate ad sets per concept.
- Budget: Modest, enough to hit 50 optimization events within 7 days.
- Creative volume: 2–5 new concepts tested simultaneously, to identify early winners.
- Decision gate: After 7–14 days, identify concepts with CPA within 20% of the target.
Validation phase: Concepts that clear your exploration thresholds move into a controlled validation environment with higher spend and conversion-focused measurement. This is where you confirm whether creative engagement actually translates to business outcomes and whether winners are repeatable.
- Structure: New ad set or ABO campaign; winner vs current BAU creative.
- Budget: Match or slightly exceed BAU ad set spend for fair comparison.
- Duration: 2 weeks minimum.
- Decision gate: Winner must beat or match BAU by your defined KPI margin.
Scaling phase: Validated winners enter your core performance campaigns with one goal: maximizing their impact before fatigue sets in. From here, the focus shifts to execution and monitoring.
- Structure: Add winning creatives to your top-performing campaigns.
- Testing: Run execution-level tests within the winning concept (hook variations, thumbnails, and CTA options).
- Duration: Ongoing.
- Decision gate: Monitor frequency and CTR weekly. Flag declining creatives for retirement.
Measuring creative performance beyond Ads Manager metrics
Ads Manager can be a useful starting point, but it doesn’t give you the full picture. Layering in additional measurement approaches can help you understand creative performance more accurately.
Statistical confidence is often overlooked in creative testing. It can be tempting to call a winner early, especially when one creative is pulling ahead in the first few days. However, early results can be misleading if the test hasn’t yet reached statistical significance.
As a general guideline, it helps to wait until you have reached at least 80% confidence. Push for 95% before making major budget decisions.
Tools like Evan Miller’s A/B calculator make it straightforward to check whether your results have crossed the significance threshold before acting on them.
ROAS is often the last metric to show signs of creative fatigue. By the time it drops, you may have already been losing efficiency for days.
Tracking signals such as rising frequency, declining CTR, or changes in CPM over time at the individual creative level can help identify fatigue earlier. This gives you time to rotate in fresh creative before performance falls.
It’s also worth looking beyond individual campaigns. A creative that performs well in one campaign may perform very differently in another depending on the audience, placement, or objective.
Regularly comparing creative performance across campaigns gives you a clearer view of which concepts consistently work and which ones only perform well in specific conditions. This becomes especially important when deciding what to scale.
Automation and tooling for creative testing at scale
When you’re managing 50+ active creatives across multiple campaigns, human review cycles are too slow and too inconsistent to keep up.
Bïrch’s Stage and Explorer can help streamline the process.

Stage lets you upload creatives in bulk directly from your computer or Google Drive. If your team works from shared Drive folders, Stage connects those folders directly to the upload flow via shared link, so assets move from Drive to your ad account without anyone downloading or re-uploading them.
From there, you can generate one ad set per creative, with consistent budget settings, audiences, naming conventions, and attribution settings applied across every test.
You can configure ad sets individually if your tests need different parameters. You can also duplicate settings across ad sets to avoid repetitive manual work.
Test structures don’t need to be rebuilt from scratch each time—templates can be saved and reused.
All this comes together to create a launch process that takes minutes instead of hours, with far less room for human error.
Explorer handles the learning and analysis phase.
It gives you a unified, visual picture of creative performance across all your campaigns and time periods. You can track performance trends with line charts, compare creatives side by side with bar charts, and filter by any KPI using a custom metric conditions builder.
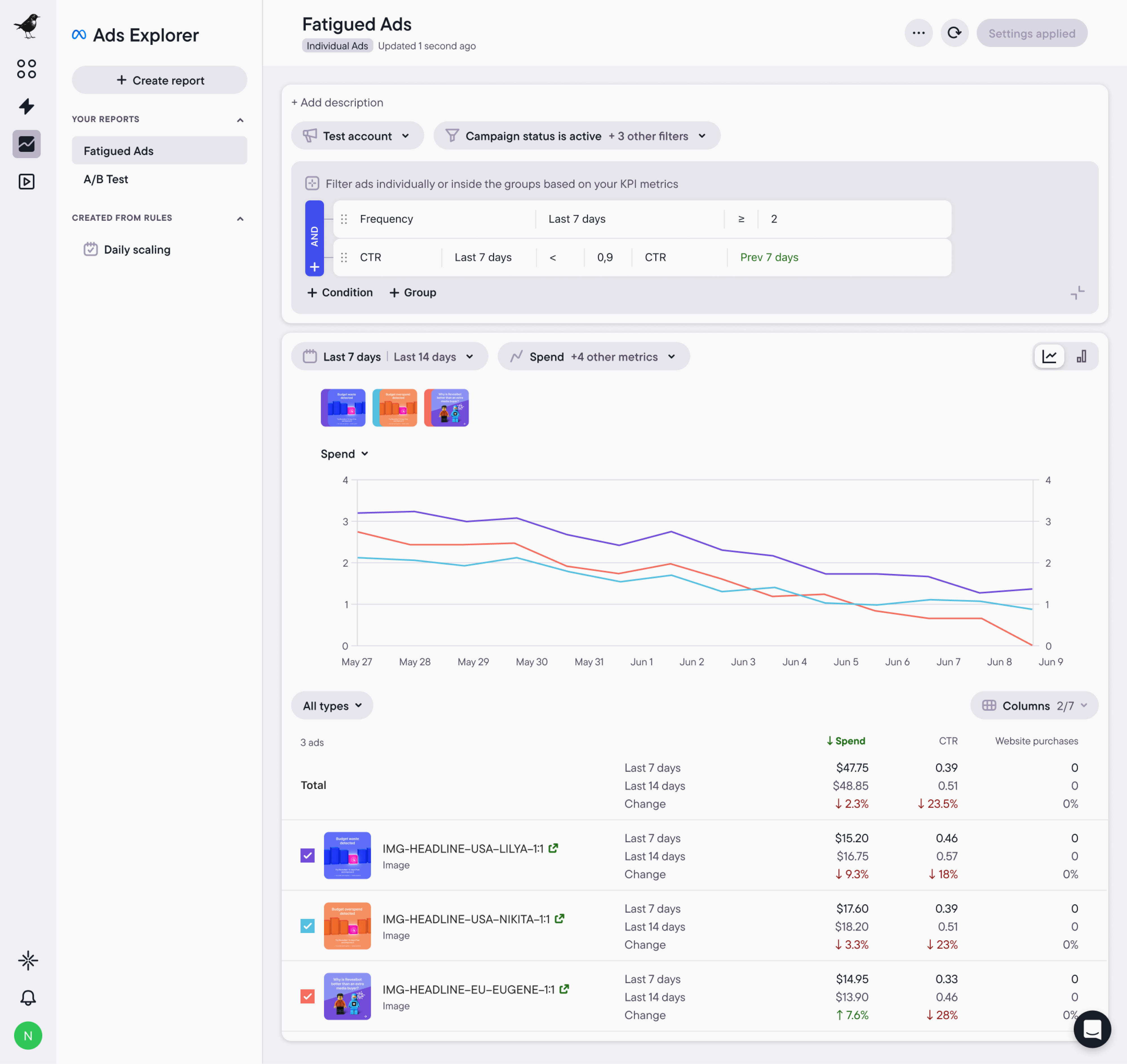
Explorer also surfaces fatigued ads and downtrending creatives before they bring down overall performance, giving you time to act.
Here’s how your team can use Stage and Explorer to build a winning system:
- Brief: Use Explorer to review performance patterns across past campaigns. Identify which concepts, formats, and hooks have consistently outperformed. Then, use this to write a hypothesis-driven creative brief.
- Build: Produce creative variants based on the hypothesis. Use Stage to pull assets directly from Google Drive via shared link, then organize your copy, URLs, and creative links in a Google Sheets spreadsheet so everything is structured and ready for Stage to map and deploy in a structured test.
- Launch: Configure your test in Stage. Set budgets, audiences, naming conventions, and ad set structure. Auto-create one ad set per creative. Save as a reusable template. Publish.
- Learn: Let the test run for a minimum of 7–14 days. It’s best to avoid reading data before adequate spending has accumulated.
- Analyze: Return to Explorer. Compare performance across campaigns, not just within the test. Does the winning creative hold up across contexts, or is it situational?
- Scale or retire: Move validated winners into your core performance campaigns, and retire creatives that show clear signs of fatigue or declining performance.
- Feedback: Document the learning. Capture which concepts, hooks, and formats performed best, and use those insights to inform the next creative brief.
Common creative testing mistakes performance teams still make
Many teams test too many variables at once. If you change the headline, the visual, the CTA, and the hook in the same test, you won’t know which variable made the difference.
Closely related is the habit of resetting the learning phase mid-test. Editing an active ad set—such as changing budgets, audiences, or creative—can restart the learning phase, which interrupts the test and makes results harder to interpret. It can also slow down optimization and waste spend while the algorithm recalibrates.
Instead, establish clear rules upfront about what constitutes an allowed mid-test edit (in most cases, none) and let the test run long enough to gather sufficient data before making changes.
Another common issue is overinterpreting early data. A creative returning 0.8x CPA in the first 48 hours is likely misleading. The algorithm is still calibrating delivery, and the attribution window is incomplete. Allow the test to run for long enough to produce a meaningful sample before drawing conclusions.
Documenting learning is equally important. Every test should conclude with a written record of what was tested, what the result was, and what the team will do differently next time. Without that record, tests stay isolated rather than contributing to a repeatable system, and the same mistakes often resurface across campaigns and teams.
Creative testing is now an operational system
The brands winning on Meta in 2026 don’t necessarily have the single best ad. They have strong testing machines, structured hypotheses, and automated decision rules.
The hard part is building a program to generate signals you can actually trust in an environment that’s noisier, faster, and more automated than it’s ever been.
Tools like Bïrch give you the operational infrastructure to build exactly that, from launching tests at scale with Stage to surfacing cross-campaign patterns with Explorer.
If you’re ready to move from ad hoc tests to a systematic creative testing program inside Meta, start your free trial and see what a strong testing workflow looks like at scale.







